ViCo-X
Multimodal Conversation Dataset
Abstract
Limited by the network latency, the in-the-wild collected ViCo dataset is hardly to capture the real-time interactions between these two interlocutors. And most of the scenarios in the vico dataset are interviews, in which the "mutual" interaction between speaker and listener is not sufficient. To thoroughly modeling the conversation, we further propose the ViCo-X dataset, the recorded face-to-face conversational videos performed by two qualified actors. Compare to ViCo dataset, alongside the improved real-time, we shift the focus from listener modeling to the dyadic interaction modeling, the multi-turn dialogues are brought in as video corpus, bringing the possibility of modeling multi-turn high-level interactions while adding a modality. And the listeners' attitudes are represented by a finer-grained context-sensitive annotations: dialog act. The dialog act can not only guide the speaker's behaviours but also affect listener feedbacks. ViCo-X dataset is constructed by 10 actors, featuring 25 dialogue scenes with 26 different dialog acts. The videos are recorded in a strictly-controlled environment to provide high quality details (2k resolution) of body postures and facial expressions. About 40 minutes of conversations are recorded, annotations are accurate to 1/30 second and the average number of dialogues is 10. We propose this dataset to encourage research interests in interaction and conversation modeling, and wish it could facilitate the applications including virtual anchors, digital influencers, customer representatives, digital avatar in Metaverse.
Dataset Details
Comparison with other human conversation-related datasets
| Dataset | Year | Public | Interlocutor | Multi-turn | Style | Environment | Head motion | Body motion | External Anno |
| GRID | 2006 | ✔ | Speaker | ✘ | Lab | Realistic | ✘ | ✘ | - |
| LRW | 2016 | ✔ | Speaker | ✘ | Wild | Realistic | ✘ | ✘ | - |
| ObamaSet | 2017 | ✔ | Speaker | ✘ | Wild | Realistic | ✔ | ✘ | - |
| VoxCeleb | 2017 | ✔ | Speaker | ✘ | Wild | Realistic | ✔ | ✘ | - |
| VoxCeleb2 | 2018 | ✔ | Speaker | ✘ | Wild | Realistic | ✔ | ✘ | - |
| LRS2-BBC | 2018 | ✔ | Speaker | ✘ | Wild | Realistic | ✔ | ✘ | - |
| LRS2-TED | 2018 | ✔ | Speaker | ✘ | Wild | Realistic | ✔ | ✘ | - |
| Faceforensics++ | 2019 | ✔ | Speaker | ✘ | Wild | Realistic | ✔ | ✘ | - |
| MEAD | 2020 | ✔ | Speaker | ✘ | Wild | Realistic | ✔ | ✘ | emotion |
| Speech2Gesture | 2019 | ✔ | Presenter | ✘ | Wild | Realistic | ✔ | ✔ | - |
| Ted Gesture | 2019 | ✔ | Presenter | ✘ | Wild | Realistic | ✔ | ✔ | - |
| Gillies et al. | 2008 | ✘ | Speaker, Listener | ✘ | Lab | Simulated | ✔ | ✔ | - |
| SEMAINE | 2011 | ✔ | Speaker, Listener | ✘ | Lab | Simulated | ✔ | ✘ | custom dimension |
| Heylen et al. | 2011 | ✘ | Speaker, Listener | ✘ | Lab | Simulated | - | - | - |
| ALICO | 2014 | ✘ | Speaker, Listener | ✘ | Lab | Realistic | ✔ | ✘ | feedback signal |
| ViCo | - | ✔ | Speaker, Listener | ✘ | Wild | Realistic | ✔ | ✘ | attitude |
| ViCo-X | - | ✔ | Conversational Agent | ✔ | Lab | Realistic | ✔ | ✔ | dialogue act |
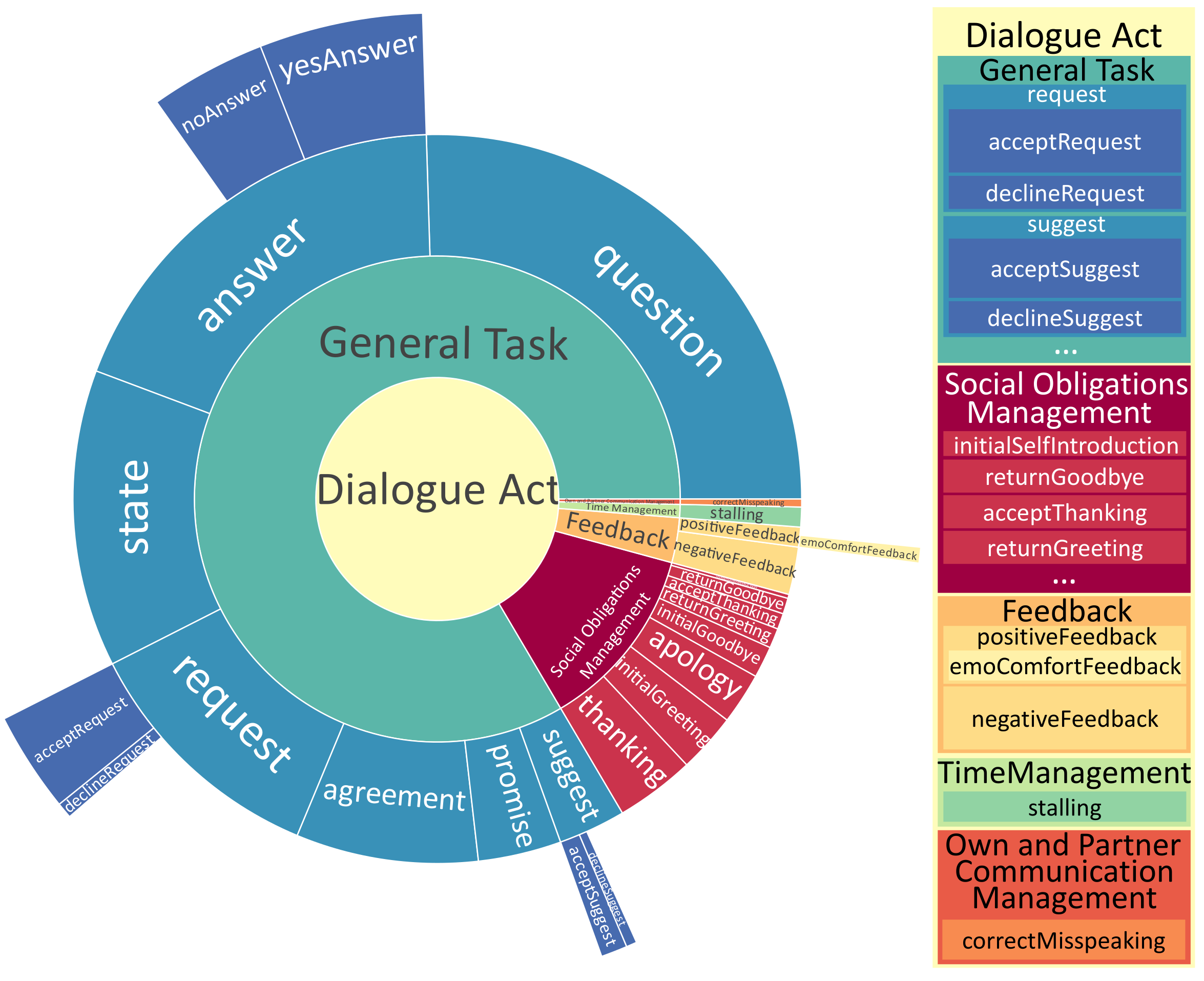
Dialogue act distribution
Identities

Example
A clip of recorded video, resized for network optimization.
| role | role_id | other_id | start_time | dialog_act | content |
|---|---|---|---|---|---|
| A | 0 | 3 | 00:00:00 | initialGreeting | 您好 |
| A | 0 | 3 | 00:00:22 | question | 请问有什么可以为您效劳的呢 |
| Q | 3 | 0 | 00:02:24 | request | 我要看一下自己在京东的历史消费 |
| Q | 3 | 0 | 00:06:01 | question | 查到了吗 |
| Q | 3 | 0 | 00:06:25 | state | 总额就可以 |
| A | 0 | 3 | 00:08:09 | noAnswer | 您好,这个总额这边是查不到的 |
| Q | 3 | 0 | 00:11:10 | negativeFeedback | 那你告诉我可以通过什么渠道查 |
| Q | 3 | 0 | 00:13:25 | question | 账单有没有 |
| Q | 3 | 0 | 00:14:20 | state | 账单也行 |
| Q | 3 | 0 | 00:15:15 | negativeFeedback | 我老婆要看,不然就说我藏私房钱 |
| Q | 3 | 0 | 00:18:17 | request | 你快帮我想想办法 |
Citation
If our dataset helps your research, please cite this website.
@misc{zhou2023interactive,
title={Interactive Conversational Head Generation},
author={Mohan Zhou and Yalong Bai and Wei Zhang and Ting Yao and Tiejun Zhao},
year={2023},
eprint={2307.02090},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Ethical Use
The ViCo-X dataset would be released only for research purposes under restricted licenses.